Echirolles/Suivi arbres
Présentation générale
La Ville d'Échirolles souhaite mettre en place un dispositif de suivi des arbres pour planifier leur plantation et leur entretien.
Il s'agit avant tout de repartir de l'existant, tant sur les données que sur le protocole de mise en œuvre.
Un travail d'inventaire avant tout...
Avant de parler de suivi, c'est un inventaire qu'il faut prévoir pour disposer d'un référentiel à jour.
C'est la condition nécessaire pour être en mesure d'assurer le travail de planification et de suivi des évènements.
... Et une coordination à trouver avec la Métropole de Grenoble (Grenoble-Alpes-Métropole)
Une partie de ce travail est à coupler avec le travail mis en place par la Métropole, qui a notamment la charge des arbres situés le long des axes de voirie dont elle a la compétence.
Ce travail est actuellement en révision et une demande a été faite pour qu'à terme la ville d'Échirolles soit directement connectée à cette base et puisse reverser ces données dans la base OSM.
Référentiel taxonomique
Un des premiers enjeux a été de définir le référentiel taxonomique permettant d'asseoir le référencement des espèces d'arbres historiquement recensées sur le territoire.
Trois référentiels ont été étudiés : TaxRef de l'INPN, BGCI et GBIF.
Malgré la grande richesse et la qualité méthodologique de ces bases, aucun de ces référentiels ne répond pleinement à notre besoin :
- TaxRef ne référence pas de nombreuses espèces issues du commerce, souvent exogènes au périmètre métropolitain et outre-mer
- BGCI ne propose pas de service de téléchargement de son référentiel complet (a priori)
- GBIF, tout comme BGCI, ne propose pas de noms vernaculaires en français
Finalement, c'est la base Wikidata qui a été choisie car elle répond à tous ces besoins, et de plus assure le rôle de base pivot aux autres référentiels taxonomiques précités.
Par ailleurs, l'atout de cette base réside dans le fait que des outils développés pour OSM (OSM-ID, MapComplete, etc.) proposent de l'autocomplétion en lien avec Wikidata pour saisir l'espèce de l'arbre, que ce soit à partir du nom latin ou des noms vernaculaires référencés dans plusieurs langues dont le français.
Processus du cycle de vie des données
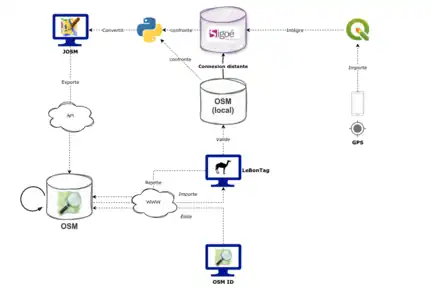
L'enjeu de ce projet est de pouvoir mettre à jour les données du référentiel dans OSM et vice versa.
Une architecture technique a donc été mise en place pour récupérer les données issues d'OSM afin de les intégrer dans le référentiel local, et, d'un autre côté, pour reverser dans OSM les ajouts et changements du référentiel local afin d'assurer un cycle de vie vertueux, notamment pour éviter d'éventuels conflits entre les deux instances.
Place centrale de l'outil LeBonTag
Cet outil permet de superviser et de récupérer facilement les objets dont nous avons besoin, en l'occurrence les arbres dans notre cas de figure.
Les données validées sont stockées dans une base PostgreSQL via la librairie osm2pgsql, qui fait office de base "locale" des données OpenStreetMap.
Reversement des données de la base locale OSM dans la base SIG métier
Pour récupérer les données issues d'OSM, un script (basé sur une fonction PL/pgsql) a été mis en place pour récupérer les changements validés depuis LeBonTag (ajouts d'objets, modifications d'attributs, etc.).
Ce script, exécuté quotidiennement par un exécuteur de tâches, fait une conflation à partir des identifiants OSM qui sont également stockés dans la base métier.
Le détail de ce mécanisme est présenté plus bas dans la section dédiée Synchronisation des données issues d'OSM.
Reversement des données de la base métier vers OSM
Pour des raisons pratiques, le travail de remplissage du référentiel de suivi des arbres consiste à saisir des données métier qui ne rentrent pas dans le cadre d'OSM. Il n'est donc pas concevable de demander à des agents de terrain de saisir des données dans deux référentiels différents.
Un outil métier unique s'impose donc dans ce dispositif, ce qui nécessite de trouver des passerelles entre nos données métier et le référentiel OSM : c'est de là que provient le besoin de faire un travail de synchronisation des données pour assurer un bon cycle de vie.
Le détail de ce mécanisme est présenté plus bas dans la section dédiée Reversement des objets du référentiel local dans OSM.
Méthodologie de structuration des données
Construction du modèle relationnel de données
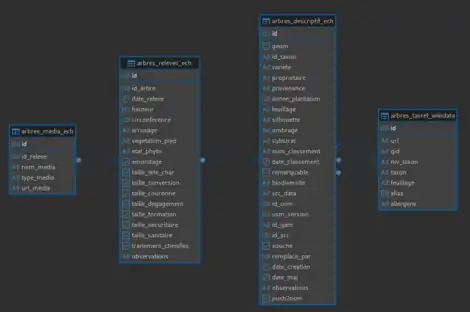
Le MCD est composé de 4 tables :
- arbres_descriptif_ech : Table de description des arbres pouvant s'apparenter à une fiche d'identification.
- arbres_releves_ech : Table de relevé terrain des arbres pouvant s'apparenter à une fiche d'identification.
- arbres_media_ech : Table des médias associés à chaque relevé de terrain.
- arbres_taxref_wikidata : Référentiel taxonomique des arbres issu de la base Wikidata et adapté aux besoins de la base de suivi.
Cette structuration de données permet de localiser, décrire et assurer le suivi des observations et de l'entretien des arbres sur le territoire échirollois.
Intégration par conflation
Composition des sources de données
La base de données croise plusieurs sources de données pour être la plus exhaustive possible :
- La base de données du patrimoine arboré de Grenoble-Alpes-Métropole : cette base de données est la plus importante en nombre d'objets. Elle comprend elle-même un inventaire issu des bases de données suivantes :
- Les arbres d'alignement de voirie
- Le plan Canopée, qui "vise à protéger les arbres existants et augmenter la plantation de nouveaux arbres, en s’appuyant sur l’indice de canopée (un indicateur traduisant la surface ombragée)"
- Les arbres protégés inscrits dans le cadre du Plan Local d'Urbanisme intercommunal
- La base de données historique construite par Échirolles avant 2023, qui se limite à un inventaire sans lien avec un référentiel taxonomique, et dont une partie de l'inventaire est redondante avec celui de la Métropole
- La base de données OpenStreetMap, qui permet d'alimenter le référentiel grâce aux contributions de la communauté
La base de données de la Métropole a déjà fait l'objet d'un travail de versement dans OSM en 2017 sur Grenoble par Binnette. Elle est aujourd'hui en cours de refonte et nécessite des travaux de stabilisation en matière de localisation, des ajustements au référentiel taxonomique mobilisé et l'affectation de codes uniques d'identification des arbres. Il est donc plus prudent de ne pas les intégrer pour le moment dans le référentiel.
Intégration par croisement des sources de données
Pour injecter l'ensemble des sources dans le référentiel de données, un script d'intégration a été construit pour effectuer les étapes suivantes :
1. Intégration des données de la Métropole dans la base historique
Ce travail a été porté initialement par une stagiaire, ce qui a permis de distinguer cette source des objets de la base historique.
La base de données de la Métro n'étant pas prête, c'est un moyen d'écraser les anciens objets avec la dernière version à venir.
2. Redressement des données liées au référentiel taxonomique
Comme évoqué plus haut, le choix s'est porté sur Wikidata pour servir de base pivot au référentiel taxonomique.
Un travail important de correspondance des valeurs a été fait manuellement pour corriger les genres / espèces des données issues de l'étape 1. Par prudence, ce travail de correspondance des erreurs est conservé dans le script global.
3. Intégration des données historiques dans le nouveau référentiel
Il s'agit de recaler les valeurs des champs avec modalités et de filtrer les champs non utiles.
Une boucle vient injecter chaque arbre dans la table descriptive, avec à chaque passage l'enregistrement du premier relevé issu des données historiques. Il s'agit en quelque sorte d'un évènement fictif puisqu'il marque le démarrage de la vie des données de la base.
4. Appariement avec les données issues d'OSM
Cette dernière partie est cruciale car elle cherche à récupérer les données issues d'OSM et à vérifier s'il s'agit d'arbres déjà présents dans le référentiel ou d'arbres qui n'ont pas encore été intégrés.
La section suivante permet de donner les détails de l'architecture mise en place.
Synchronisation des données issues d'OSM
Le travail de synchronisation se déroule selon les étapes suivantes :
- Récupération des données des arbres de la base OSM locale. Pour consolider ces données (absence d'information sur la phénologie, etc.), un travail de croisement est effectué avec le référentiel taxonomique dans l'éventualité de la présence d'informations comme le genre ou l'espèce.
- Intégration de nouveaux codes Wikidata issus d'OSM si ceux-ci ne sont pas présents dans le référentiel Wikidata local.
- Mise à jour des attributs des objets existants du référentiel local pour lesquels il existe une version plus récente validée depuis LeBonTag.
- Insertion des objets (issus d'OSM) qui ne sont pas dans le référentiel local.
- Suppression des objets du référentiel local dont l'identifiant n'est plus présent dans la base locale OSM.
Reversement des objets du référentiel local dans OSM
Principe
Cette fonctionnalité permet de conserver le cycle de vie synchronisé des données entre OSM et le référentiel local. C'est un moyen de reverser dans OSM un objet qui pourrait apparaître en parallèle par le biais d'un contributeur OSM, et qui générerait un conflit lors de la phase de synchronisation.
Étapes de fonctionnement
- Chaque objet créé ou modifié localement est tagué pour être éligible à son versement dans OSM.
- Les objets tagués sont filtrés au travers d'une vue dont les champs correspondent aux noms des tags à téléverser.
- Les données de la vue sont converties au format .osm par l'intermédiaire d'un script python de telle manière que :
- les objets ayant une existence dans OSM seront mis à jour avec un nouveau numéro de version.
- les objets créés dans le référentiel local, qui n'ont pas d'existence apparente dans OSM, seront reversés pour la première fois dans OSM et l'identifiant créé sera récupéré à la synchronisation suivante, comme expliqué dans la section décrite plus haut.
- Le fichier.osm généré est chargé dans JOSM puis téléversé.
- Le tag des objets candidats au reversement est réinitialisé dans la base du référentiel en vue du prochain reversement.
Ainsi, il s'agit d'un travail de contrôle semi-automatique (de la même manière que pour la phase d'intégration) effectué en amont pour repérer ce qui a pu se faire entre temps dans OSM, au travers d'une vue au format "compatible OSM" des objets tagués :
- Vérification d'un arbre à proximité pouvant être le même
- Contrôle sur le changement des attributs suivis dans le cadre du projet
Cette tâche est programmée de façon régulière (dont la fréquence est décidée avec l'équipe du projet) pour garder une cohérence entre les deux référentiels par l'intermédiaire d'une supervision humaine.
Focus sur le script python
Le script python est un travail issu d'une source fournie à l'origine par Ptigrouick (que je remercie encore une fois !) qui :
- récupère dans la base PostgreSQL les arbres à téléverser dans un format compatible avec OpenStreetMap
- récupère depuis l'API d'OpenStreetMap les arbres
- croise ces deux sources afin :
- d'appareiller les arbres ayant le même identifiant OSM
- de considérer les autres arbres du référentiel local comme de nouveaux arbres
- génère au format OSM les résultats de ce croisement
Il est à noter que ce croisement se fait de façon supervisée dans le sens où les données du référentiel local sont contrôlées au préalable depuis l'outil LeBonTag.
Évolutions à envisager sur le mécanisme de reversement
Une réflexion est en cours pour faciliter ce travail de reversement par le biais d'une interface ergonomique, avec la consultation d'éditeurs SIG pour OSM.
Suivi physiologique et phytosanitaire : proposition de tags spécifiques
Pour enrichir le travail de terrain, il est proposé de rajouter deux nouveaux tags relevant de l'état de santé de l'arbre : son état physiologique et phytosanitaire.
Après analyse des données présentes dans OSM, la question de l'état de santé de l'arbre ne semble pas être prise en compte et cela pourrait avoir un intérêt de spécifier cette information pour faire remonter des alertes aux propriétaires des arbres.
En s'appuyant sur l'expertise de l'ONF[1], il est proposé de porter l'information de l'état de santé sur deux tags différents :
health:physio_statuspour l'état physiologiquehealth:phyto_statuspour l'état phytosanitaire
Pour chacun d'entre eux, 3 niveaux d'état sont proposés (good, average et bad), dont l'affectation de la valeur pourrait se faire de la manière suivante :
| health | good
|
average
|
bad
|
|---|---|---|---|
| physio_status | Arbre en bonne santé, croissance active des rameaux | Présence de petites branches mortes, baisse de vitalité, croissance réduite | Arbre dépérissant, nombreux éléments morts, descente de cime, gourmands fréquents sur les charpentières, croissance des rameaux quasi nulle, perte anormale de feuilles supérieure à 30 % |
| phyto_status | Arbre sain | Présence de champignons ou d’insectes pouvant affecter à terme le fonctionnement de l’arbre ou sa solidité. | Attaque importante d’insectes ou de champignons menaçant la survie ou la solidité de l’arbre. |
- ↑ Rapport de l'ONF, 18 arbres sur espaces publics à Échirolles, 2017